Chiến dịch/Kế hoạch/Chương trình Phụng Hoàng/Phượng Hoàng (tiếng Anh: Phoenix Program) (1968-1975) là chiến dịch tình báo, ám sát bí mật trong Chiến tranh Việt Nam được tiến hành bởi Phủ Đặc ủy Trung ương Tình báo Việt Nam Cộng hòa (CIO) với sự phối hợp của Cục Tình báo Trung ương Hoa Kỳ (CIA).[1] Chương trình này được hoạch định với mục đích phát hiện và “vô hiệu hóa” – bắt giam, chiêu hàng, giết, hoặc kiềm chế – các cán bộ Mặt trận Dân tộc Giải phóng miền Nam (MTGP) nằm vùng, những người tuyển dụng và đào tạo cơ sở cho quân Giải phóng tại các xã ấp miền Nam Việt Nam, cũng đồng thời là những người hỗ trợ các nỗ lực đấu tranh vũ trang

Đây không phải là một bài viết về lịch sử chiến tranh nên các bạn muốn tìm hiểu thêm thì xem bằng Youtube cho nhanh
Bộ trưởng Quốc phòng lúc bấy giờ, Robert McNamara, nhằm định lượng càng nhiều cuộc chiến càng tốt bằng máy tính. Một trong những nỗ lực tốn kém nhất của McNamara là Hệ thống Đánh giá Ấp Chiến lược, cố gắng định lượng mức độ bình định của khoảng 12.000 ấp chiến lược ở nông thôn Việt Nam. Một báo cáo của RAND cho thấy chương trình này đã tạo ra 90.000 trang dữ liệu mỗi tháng. Nhiều kỷ lục những gì có thể từng được sử dụng thời đó.
Đây là dữ liệu được tạo ra chỉ bằng một chương trình đo lường thời chiến. Ngay cả khi Bộ Quốc phòng có sức mạnh tính toán thô sơ của những năm 60 và đội ngũ lập trình viên FORTRAN cần thiết để xử lý tất cả đống dữ liệu này.
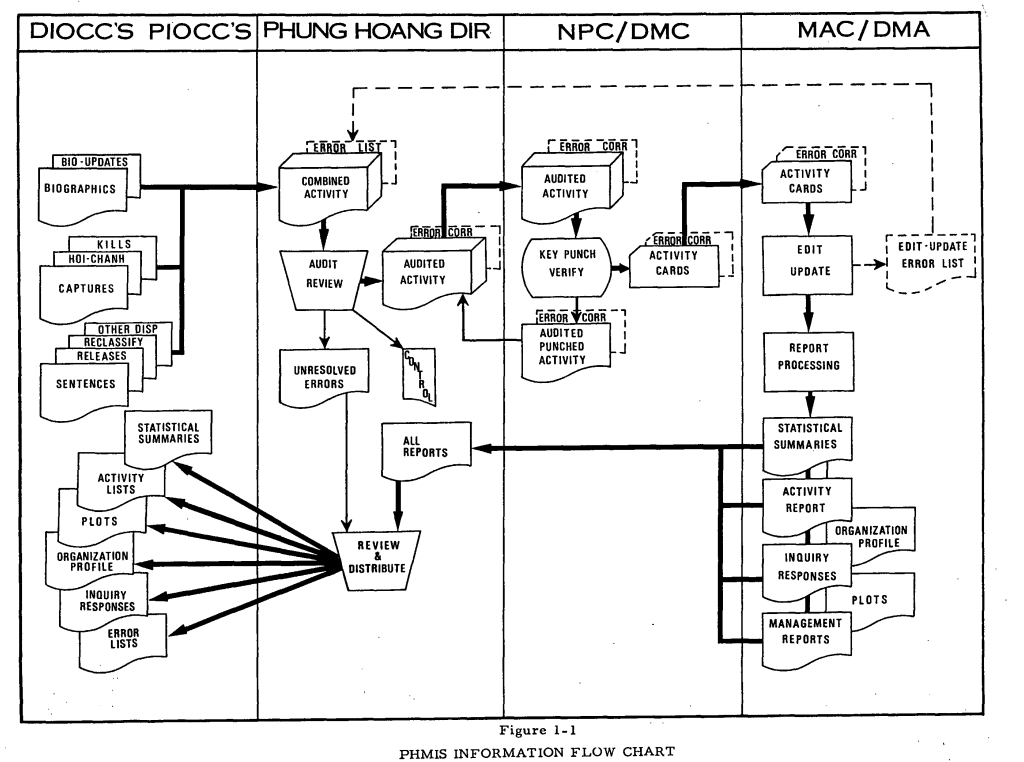
Hệ thống này gọi là Phung Hoang Mangement Information System (sau đây viết tắt là PHMIS) , mình để cái flowchart ở dưới đây
Các lập trình viên Fortran ngày đó cần tương tác với một tấm bìa để đưa mã lập trình hay dữ liệu vào máy tính . Nó sẽ nhìn thế này .

Với công việc tỉ mẩn thế này thì không khó hiểu khi đa phần các Lập trình viên thời đó là phụ nữ

Theo Sắc lệnh Điều hành 13526 của Mẽo thì các tài liệu sẽ phải công khai sau 25 năm . Nhưng CIA thì hơi ảo , một là họ đóng dấu tuyệt mật, hoặc là coi đó là tài liệu nội bộ , hay công khai một phần . Trong hệ thống PHMIS họ công khai một phần và cũng không cung cấp công cụ giải mã . Tuy nhiên lại có cả tài liệu thiết kế nên chỉ cần bỏ công code là làm được .
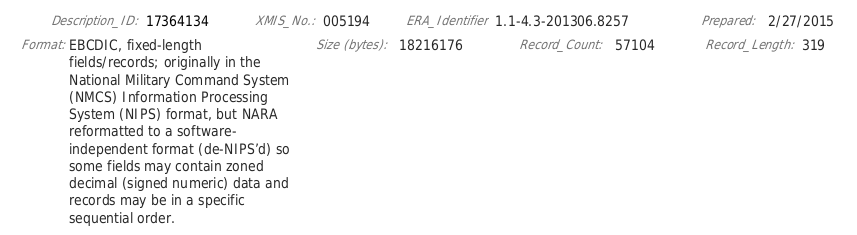
Đây là trang dữ liệu được public về PHMIS
https://catalog.archives.gov/id/17364134
Trong đó “222.1DP.pdf” là Technical Document còn file chính là một file nhị phân “RG330.PHMIS.P6972”
OK . Biết thế đã , giờ đọc tài liệu để đọc cái file củ mật kia nào . Đầu tiên ta chú ý đến độ dài của một bản ghi
Chính xác thì nó luôn bằng 319 . Vậy thì chặt ra thành các đoạn có độ dài bằng 319 đã rồi tính tiếp.
Mà thôi đọc 319 byte đầu xem nào

Oắc đờ hợi nó ra cái cục shit gì thế này
sao lại là 0xf0 ký tự này mà ở ascii thì nó là cái chữ Lào nào ấy

Thử decode ra xem nào
Đúng như dự đoán nó không decode được
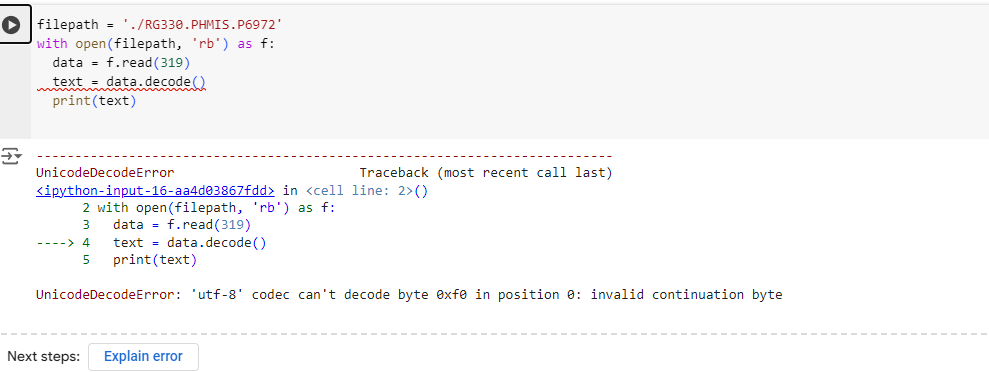
Đến đây tôi nhận ra mình quá ngu , ngày đó làm éo gì có chuẩn Unicode hay có khí còn chưa có ASCII
Search lại thì ra cái link của máy IBM xem nào, kết hợp với cái chuẩn củ mật kia xem
https://www.ibm.com/docs/en/i/7.5?topic=encodings-fileencoding-values-i-ccsid
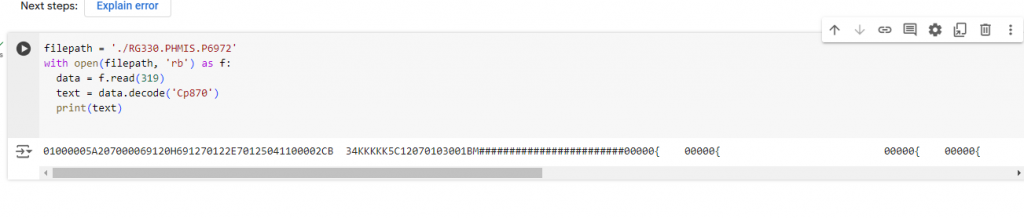
Khá hơn nhiều rồi nhưng có cái dấu { và 1 tỷ dấu # kia là thế nào nhỉ .
Có vẻ dấu Ơ hiểu là kết thúc cái data. còn cái dấu # kia sau 1 hồi tra lại tài liệu thì cái đấy đơn giản là tên riêng bị che đi khi public tài liệu . Humm

Giờ thì ta có 1 chuỗi vẫn khá ngu học là 01000005A207000069120H691270122E70125041100002CB để hiểu nó là cái gì thì phải dựa vào tài liệu mô tả cấu trúc
Nhìn vào tài liệu ta thấy phần dữ liệu đầu tiên là Control Set mà phần đầu của nó chính là mã tỉnh (PROCV) có độ dài là 2
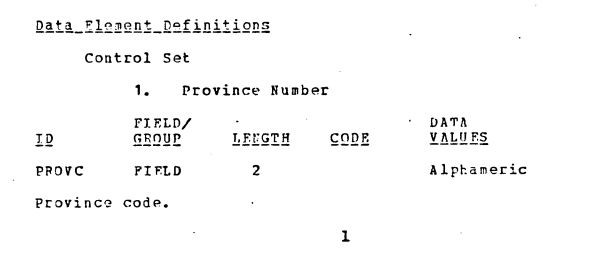
Và tra vào bảng mã tỉnh sau
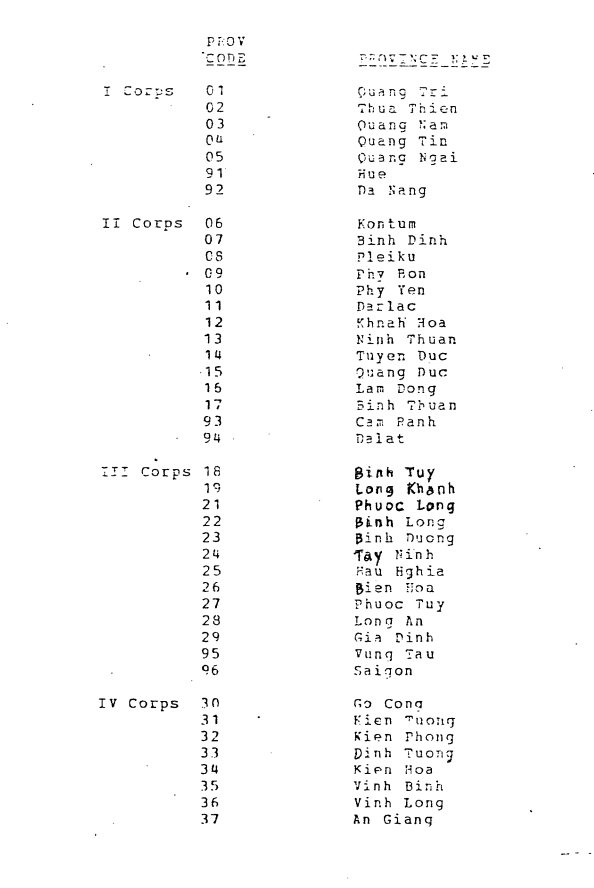
Có thể thấy bản ghi đầu tiên 01000005A207000069120H691270122E70125041100002CB
xảy ra ở 01 tỉnh Quảng Trị, hài lại phải làm vài mapping cho để lấy cái tên tỉnh . Mà thôi để sau đi.
Giờ thì hay rồi, dự đoán là khó khăn phía trước sẽ như leo Tam Đảo rồi. Hi vọng là mình chưa già .Có 2 cách để đi tiếp từ đây , 1 là căn cứ trên cái tài liệu tách từng trường ra bằng code .
Cách khôn hơn là dùng AI. Tôi thì không ngu rồi nên tôi chụp ảnh tài liệu , ghép thành 1 file ảnh duy nhất

Rồi giờ là dùng AI để lập bảng ( cảm ơn bạn Claude 3.5 Sonet)

Ngon rồi , giờ nhét vào code thôi

Trong mô tả thì trường bắt đầu theo kiểu start-end tức là vị trí ban đầu và kết thúc của trường , tuy nhiên ông python thì index bắt đầu từ 0 chứ không phải từ 1 , và các trường ví dụ ALTRG lại chỉ có vị trí bắt đầu phải sửa lại chỗ này để trừ index , và bù cho các trường chỉ có vị trí bắt đầu . Code này là AI viết hehe
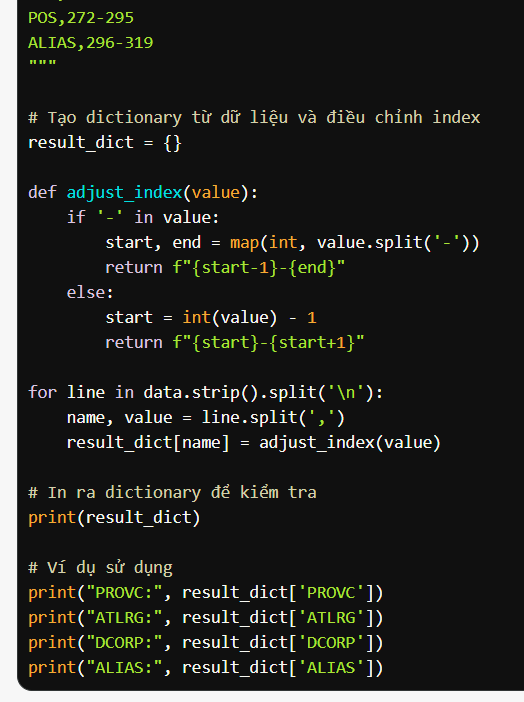
Rồi giờ decode ra một file đã , sau đó tách bảng và lưu vào 1 file csv để dùng sau này
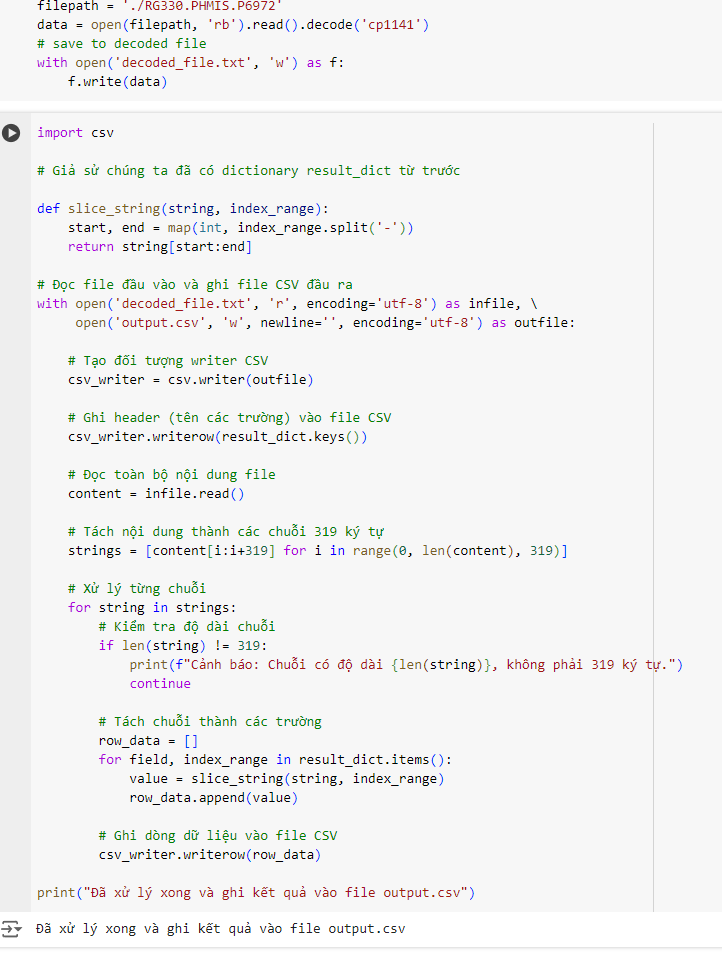
Tiếp theo cần tách các trường ngày tháng năm , các trường tổng hợp như trường ORDIND ARREST …
Có vậy mới ra được thông tin giá trị , để tạo ra hành trình bị bắt , bị giết hay được thả , thả xong thì đi đâu ..
Vậy giờ công việc có thể làm tiếp bằng các kỹ thuật của DA/DE thông thường
https://docs.google.com/spreadsheets/d/10FvKGwTpKOQ8baXnji5WbS61TV-JQ0u1QIzehoxaE-E/edit?usp=sharing
Tách ORDIND theo trạng thái kiểu như nếu nó chứa K thì là Killed
import pandas as pd
# Đọc file CSV
df = pd.read_csv('output.csv')
# Định nghĩa từ điển ánh xạ ký tự với ý nghĩa
status_dict = {
'K': 'Killed',
'C': 'Captured',
'R': 'Rallied',
'1': 'Sentenced less than six months',
'2': 'Sentenced six months or more, but less than one year',
'3': 'Sentenced one year or more, but less than two years',
'4': 'Sentenced two years or more',
'E': 'Released as a result of processing',
'F': 'Referred to military court',
'G': 'Referred to civilian court',
'H': 'Referred to another province',
'I': 'Banished',
'M': 'Military service (drafted)',
'P': 'Classified POW',
'T': 'Reclassified as Hoi Chang',
'U': 'Unaccounted for - not known to be in any detention facility - nor is there any record showing that he has been processed by the PSC or military court',
'W': 'Released prior to being forwarded for processing',
'X': 'Died after capture',
'Z': 'Escaped',
'O': 'Other'
}
# Tạo các cột mới dựa trên từ điển
for key, value in status_dict.items():
df[value] = df['ORDIND'].fillna('').astype(str).str.contains(key, case=False).astype(int)
# Xóa cột ORDIND gốc nếu không cần thiết
# df = df.drop('ORDIND', axis=1)
# Lưu DataFrame đã được xử lý vào một file CSV mới
df.to_csv('processed_output.csv', index=False)
print("Đã xử lý xong và lưu vào file 'processed_output.csv'")“`